Nova
- Agent Runtime
- Harness
Model-agnostic agent runtime that manages long context, provides tracing, tools and event streaming. Has RAG-based memory system, a trace viewer and cron job scheduler as additional plugins
Architecture
Why I built this
You could be reading this and wondering, "What does this do that Claude Code, Codex, OpenClaw, etc. doesn't?" The answer is nothing. Or nothing really of note. I started this project all the way back in fall 2025, pre-OpenClaw and when Codex was mud and sticks.
Nova started as a voice agent on a Raspberry Pi, which I moved away from after I ported it from Python to TypeScript and did not want to mess with a new VAD/beamforming package.
I made a lot of mistakes and learned a lot of lessons.
Plan, Execute, Reflect as built-in program scaffolding
This was restrictive, slow, and carried way too much task state in program memory. I had an epiphany: "Let them cook." The harness should not be opinionated about "how" the agent works. You provide the boundaries, or the "what" it can do.
Testing with a slow model to save money
Shoutout to Z.ai. The GLM series is great, but they are SLOW. You will be tempted to use a subscription to a Chinese open-source lab when wasting tokens iterating early on. I would advise against it. This mistake was made worse by the API not supporting structured outputs, and the tool-calling accuracy I would call a "mixed bag" if I were trying to be charitable. If I were trying to be negative, I would call it a "mixed bag" because a blind man reaching into a mixed bag of my tool definitions would have pulled the right one out just as often. And he might even have remembered to fence his JSON.
Observability
If you don't have something for observing traces locally, build one. It will not take long. This is table stakes. Feedback loops matter.
Parent-dispatched subagents over parallel agents
With parallel agents, I often found that the juice wasn't worth the squeeze. It quickly becomes a coordination problem. The issue is that each agent has it's own context window, and each agent is writing to the environment. As you add more agents to the environment, the source of truth is being overwritten faster and thus the agent's context windows become stale. You need to somehow coordinate these agents to work on separate sections, or you would need to somehow update the respective sections of every context window every time an agent writes. Subagents dispatched in parallel by a parent were stronger because of centralizing *intent*. This provides much better up-front coordination. Intent originating from a single brain sacrifices maximum parallelism but greatly reduces the amount the agents collide and cause the stale read issue.
Screenshots
Pictured above is the Nova TUI.
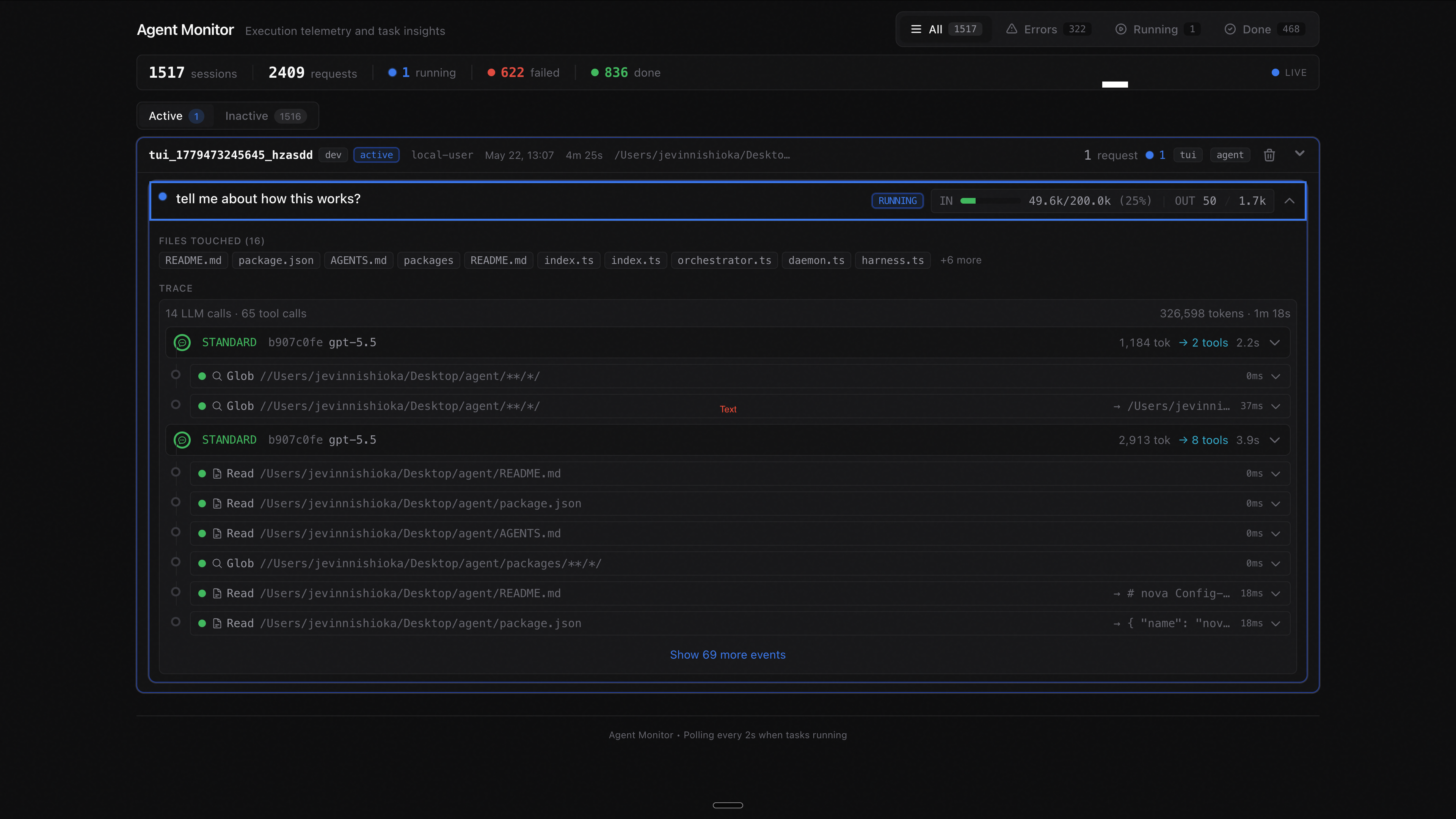
This is the trace viewer I built. A bit heavy, but I may as well put my 64GB of RAM to work.